
How project "BackRub" turned into the original Google Search algorithm and the origins of "PageRank"
In 1995 Larry Page and Sergey Brin were Ph. D. students at Standford University. Their research was the beginning of an exciting period for Page and Brin. They began working on a research project called “BackRub” with the aim of classifying internet sites into a scale of importance by using their backlink data. Without realizing it, Page and Brin created the initial Google Search algorithm when collaborating on BackRub that year.
By 1998 Google had indexed around 24 million web pages. Furthermore, Google was seen as the “best” of the search engines compared to Hotbot, Excite.com, Yahoo! because it served up more relevant search results to the user.
The goal of Page and Brin was to reduce the number of irrelevant pages that most queries were matching; they noted “too many low-quality matches”. However, Page and Brin went on to notice how Google was different. Its main goal was to “improve the quality of web search engines” by using both linking and anchor text.
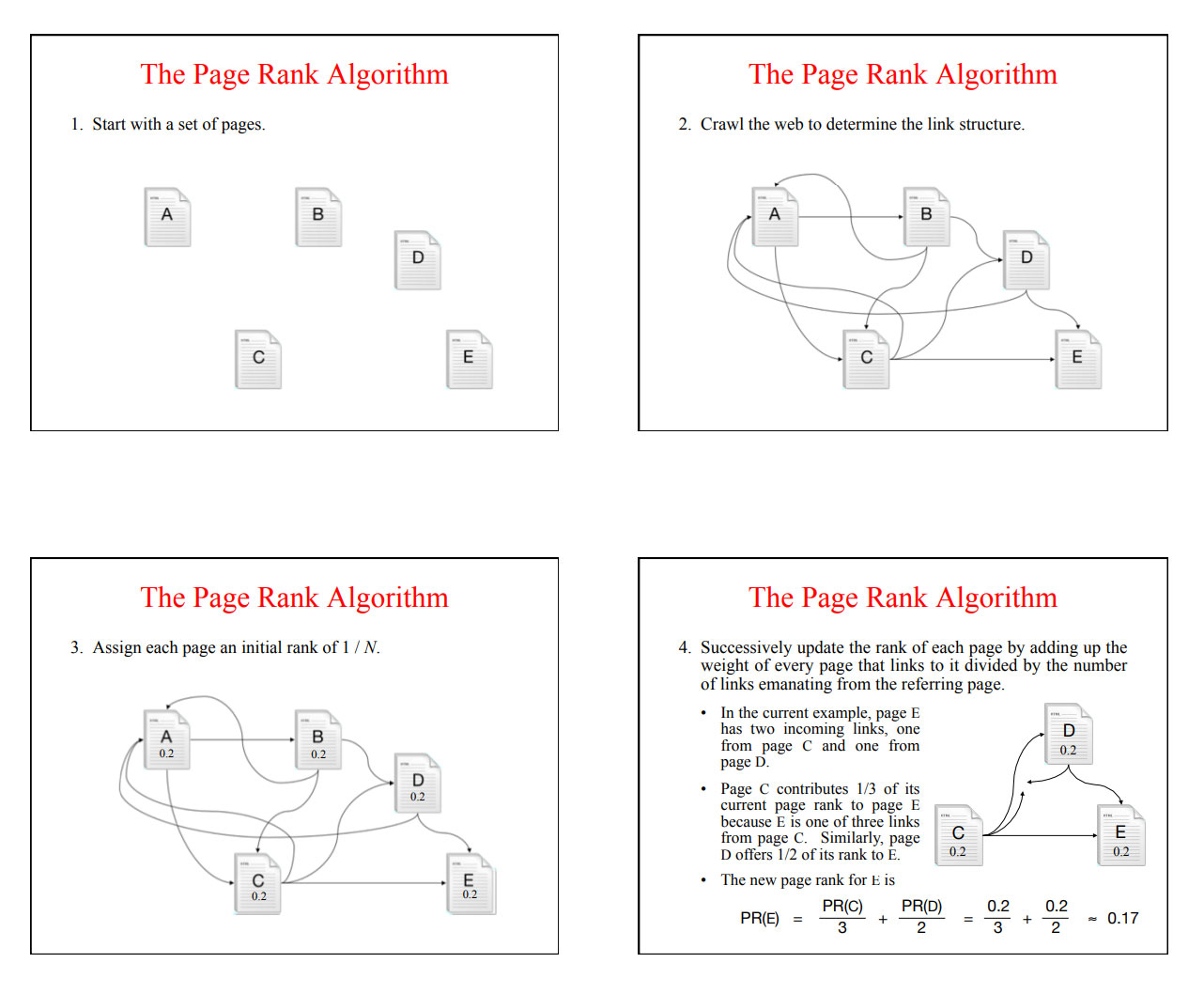
Page and Brin coin the term “PageRank” and defined it “as an objective measure of a page’s citation importance that corresponds with a person’s subjective idea of importance.”
The following is directly from the original paper, and it is fascinating how they foresaw the future of search and classification rankings.
2.1.2 Intuitive Justification
PageRank can be thought of as a model of user behavior. We assume there is a “random surfer” who is given a web page at random and keeps clicking on links, never hitting “back” but eventually gets bored and starts on another random page. The probability that the random surfer visits a page is its PageRank. And, the d damping factor is the probability at each page the “random surfer” will get bored and request another random page. One important variation is to only add the damping factor d to a single page, or a group of pages. This allows for personalization and can make it nearly impossible to deliberately mislead the system in order to get a higher ranking. We have several other extensions to PageRank, again see [Page 98].Another intuitive justification is that a page can have a high PageRank if there are many pages that point to it, or if there are some pages that point to it and have a high PageRank. Intuitively, pages that are well cited from many places around the web are worth looking at. Also, pages that have perhaps only one citation from something like the Yahoo! homepage are also generally worth looking at. If a page was not high quality, or was a broken link, it is quite likely that Yahoo’s homepage would not link to it. PageRank handles both these cases and everything in between by recursively propagating weights through the link structure of the web.
2.2 Anchor Text
The text of links is treated in a special way in our search engine. Most search engines associate the text of a link with the page that the link is on. In addition, we associate it with the page the link points to. This has several advantages. First, anchors often provide more accurate descriptions of web pages than the pages themselves. Second, anchors may exist for documents which cannot be indexed by a text-based search engine, such as images, programs, and databases. This makes it possible to return web pages which have not actually been crawled. Note that pages that have not been crawled can cause problems, since they are never checked for validity before being returned to the user. In this case, the search engine can even return a page that never actually existed, but had hyperlinks pointing to it. However, it is possible to sort the results, so that this particular problem rarely happens.This idea of propagating anchor text to the page it refers to was implemented in the World Wide Web Worm [McBryan 94] especially because it helps search non-text information, and expands the search coverage with fewer downloaded documents. We use anchor propagation mostly because anchor text can help provide better quality results. Using anchor text efficiently is technically difficult because of the large amounts of data which must be processed. In our current crawl of 24 million pages, we had over 259 million anchors which we indexed.
The full paper can be viewed at: http://infolab.stanford.edu/~backrub/google.html. It’s a 15-minute read that provides a concise explanation of Google’s original algorithm, which led to it becoming one of the world’s most influential companies.
Clients











